Sentimental Robot reads the news
I recently completed a small project to get back into working with serverless and to learn about Amazon Comprehend.
In AWS’s own words, Comprehend ‘is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text.’
Using this and a few other services, I created a sentimental robot which reads the news. More precisely, it grabs the top 10 BBC headlines each morning, chugs them into Comprehend for a sentiment analysis, and lets the user see the past few days’ analyses.
I might publish a more detailed walk-through of how this was built, but below are my high-level notes and links to the Github repos.
Backend: Lambda, Comprehend, Cloudwatch, DynamoDB, and API Gateway
The Github repo for the backend can be found here.
Collecting, analysing and storing the headlines
A Cloudwatch Rule is set to trigger a Lambda function to run every day at 10AM.
This Lambda:
- scrapes the top 10 headlines from the BBC’s website (bbc.co.uk),
- it then makes a request to the Comprehend service, providing the headlines,
- finally, it formats the results and puts them into a DynamoDB table.
Allowing the frontend to query the headlines database table
Through API Gateway, I made available the endpoint https://gp7dnv8i52.execute-api.eu-west-1.amazonaws.com/dev/getlatestbbc/ that the client can make GET requests to.
A GET request to this endpoint triggers a Lambda which queries the DynamoDB table for the past 7 days’ headlines and their analyses.
Frontend and hosting/distribution: React, Bootstrap, s3, and CloudFront
The Github repo for the frontend can be found here.
The frontend is a very simple React app, using React Bootstrap for styling (in particular, for the ‘Accordion’ that displays the result for each day and more info when clicked).
It’s hosted out of an s3 bucket and distributed globally through CloudFront.
Not having used s3 for hosting a website before, and having never used CloudFront at all, I googled around and found an excellent resource that made it super simple: Serverless Stack – highly recommend it and wish I’d had the whole guide much earlier!
I found an error in the guide and since I found it so valuable I used this as an opportunity to make my first (small) open source contribution.
Potential next steps / stuff that is broken
There are a few things I know are broken or could be improved, some of which I might do at one point!
Firstly, the sentiment analysis seems weird sometimes… Was 31 May really positive?
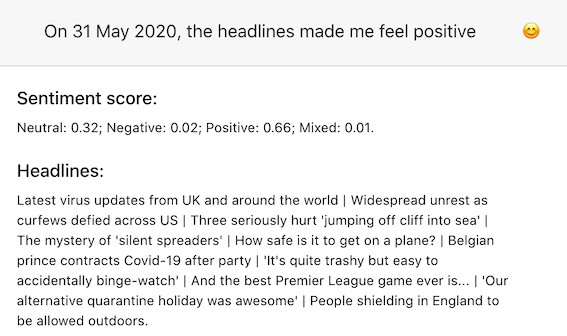
Second, the only thing you can get from the frontend is the past 7 days’ headlines and their analyses, but perhaps there’s something more interesting to be done with the increasing amount of historical data I’ll have available. Tbd! E.g. something like what Hedonometer.org did here.
Finally, there are lots of things that are not ‘production’-ready here that I am not going to spend time fixing, at least for now. For example, I don’t have any proper error handling and I just let my IAM role permissions apply to all resources using the wildcard statement, ‘*’.